java是如何通过JDBCAPI访问数据库的?
其实Java如何通过JDBCAPI访问数据库的,我们先来看看下图:
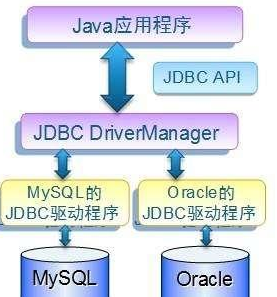
通过图片我们可以看出来,Java程序需要做数据库操作通过jdbcAPI做操作,在做操作之前同DriverManager来建立连接。在建立连接之前我们要加载对应要连接数据库的驱动,所以驱动需要数据库厂商自己提供。
整理出来Java连接数据库的操作基本的流程是:
-
加载驱动;
-
建立连接;
-
执行sql;
-
处理结果;
-
关闭资源;
通过这五个步骤我答主来一一解释如何访问的数据库
加载驱动
我们得知道自己连接是数据库是哪一类,所以得先加载需要连接数据库的驱动,这个驱动我们要提前引入。我就用mysql为例,代码如下:
Class.forName("com.mysql.jdbc.Driver");
建立连接
驱动加载完毕我们的和这个数据库建立连接,所以我们要在建立连接的时候给上连接地址,登录名,登录密码;这里会产生一个连接对象Connection;
Connection conn=DriverManager.getConnectioin("jdbc:mysql://服务器地址:3306",登录名,密码);
发送并执行sql语句
有了连接对象Connection,那么我们就可以发送并执行sql语句了,这个时候需要一个做发送执行的对象Statement对象,这个对象是有Connection产生。然后根据对应的sql语句类型调用对应的执行方法;
Statement sta=conn.creatStatement();
//执行sql语句,这里用查询举例,会得到一个结果集对象。
ResultSet rs=sta.executeQuery(sql语句);
处理结果
这里执行的是查询sql语句,那么会得到一个获得结果集的对象ResultSet对象。也就是说我们处理结果集就是在操作这个对象:
rs.next();//问有没有
String a=rs.getString("字段名或下标");//有就取,这行数据的某个字段
int b=rs.getInt("字段名或下标");
关闭资源
刚刚做完操作,现在我们需要对使用过的资源对象做关闭操作;
要遵循后用先关的规则:
rs.Close();
sta.Close();
conn.Close();
总结:大家可以看到通过我们以上的步骤可以看出来,我们通过api连接数据库的步骤就是这个样子的。











