Jmeter性能测试系列——性能测试工作实施(指标分析与定义)(二)
发布日期:2019-07-10 来源:汇智动力
图1响应时间组成示意图
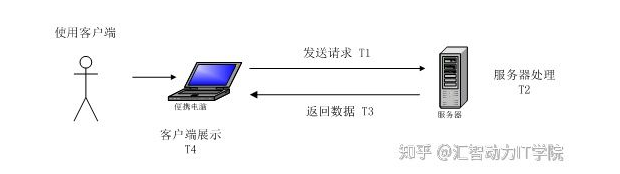 通过上述两个不同视角的描述不难发现,用户与服务器所理解的响应时间存在明显的差异。用户关注的是发出请求至看到响应结果的时间,而服务器关注的是接受请求到返回结果的时间,对于用户而言,忽略了浏览器展示的时间,对于服务器而言,则忽略了浏览器展示、网络传输等时间。因此,在实际测试过程中,需明确以什么视角验证被测对象的性能。
通过上述两个不同视角的描述不难发现,用户与服务器所理解的响应时间存在明显的差异。用户关注的是发出请求至看到响应结果的时间,而服务器关注的是接受请求到返回结果的时间,对于用户而言,忽略了浏览器展示的时间,对于服务器而言,则忽略了浏览器展示、网络传输等时间。因此,在实际测试过程中,需明确以什么视角验证被测对象的性能。
大多数情况下,性能测试主要是以用户视角进行,因此在实际测试过程中,通常关注用户行为,所以,响应时间一般指客户端发出请求到接收到服务器端的响应数据所消耗的时间。
需注意的是,性能测试工作中,客户有时可能需要测试公网的系统来验证性能指标,从测试经验来看,最好不要尝试在公网进行性能测试,原因有二:
第一、 可能影响现网用户。实施性能测试过程中,可能产生大量的压力与垃圾数据,从而破坏生产环境,导致缺陷的产生,影响实际的业务。
第二、 压力模拟可能无法真实体现。性能测试工程师实施性能测试时,利用测试工具,模拟了大量的并发数,产生了大量的业务数据,但因负载生成器所在的网络与服务器所在网络不同,或者服务器的网络安全设置,导致压力数据无法达到被测服务器,整个网络环境不可控,从而导致测试失败。
有一种情况除外,模拟固定带宽网络访问的场景,可在局域网中使用限制带宽的手段进行测试。遵循一个原则,测试过程中,任何资源都必须可控。
3、吞吐量
单位时间内系统处理用户请求的数量,可以用请求数/单位时间或者点击数/单位时间,或者字节数/单位时间等方式来衡量,其中通过字节数/单位时间的计算方式,与当前的网络带宽比较,可以找出网络方面的问题。例如,1分钟内系统可以处理1000次转账交易,则吞吐量为1000/60=16.7。吞吐量指标直接体现了软件系统的业务处理能力,尤其适用于系统架构选型,做对比测试。
4、系统资源耗用
系统资源耗用,客户端与服务器系统各项硬件资源的耗用情况,如CPU使用率、内存使用率、网络带宽占用率、磁盘I/O输入输出量等。一个系统的高效运行,除了软件资源外,硬件资源也是不可缺少的部分,因此在性能测试过程中,需关注系统资源的耗用。
5、业务成功率
业务成功率意为用户发起了多笔业务请求,成功的比率有多少。例如,测试银行营业系统的并发处理性能,全北京100个网点,中午12:30到13:30一个小时的高峰期里,要求能支持50000笔开户业务,其中成功率不少于98%,也就是需要成功开户49000笔,其他的1000笔可能是超时,或者其他错误导致未能开户成功。业务成功率展示了在特定压力或负载情况下,服务器正确稳定处理业务请求的能力。
6、TPS
单位时间内服务器处理的事务数,该指标值越大越好。一般情况下,用户业务操作过程可能细分为若干个事务,单位时间处理的事务数越多,说明服务器的处理能力越强。
根据上述各个指标的概念,结合被测对象本身的业务情况,做出如下测试需求及指标分析。
ECShop是一个面向广大网络用户的电子商务系统。大部分用户会在某个时间段访问该电商平台,进行网络购物,但如何确定用户访问的时间段呢?
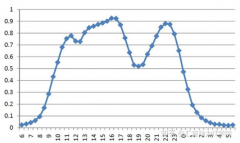
新系统没有上线时,没有历史数据可以依据,这种情况下,测试工程师可以通过竞品分析,获取友商系统的运营数据作为参考。以淘宝运营数据为例,通过运营团队统计,大部分消费者集中在如图2所示的时间段访问电商平台。
大多数情况下,性能测试主要是以用户视角进行,因此在实际测试过程中,通常关注用户行为,所以,响应时间一般指客户端发出请求到接收到服务器端的响应数据所消耗的时间。
需注意的是,性能测试工作中,客户有时可能需要测试公网的系统来验证性能指标,从测试经验来看,最好不要尝试在公网进行性能测试,原因有二:
第一、 可能影响现网用户。实施性能测试过程中,可能产生大量的压力与垃圾数据,从而破坏生产环境,导致缺陷的产生,影响实际的业务。
第二、 压力模拟可能无法真实体现。性能测试工程师实施性能测试时,利用测试工具,模拟了大量的并发数,产生了大量的业务数据,但因负载生成器所在的网络与服务器所在网络不同,或者服务器的网络安全设置,导致压力数据无法达到被测服务器,整个网络环境不可控,从而导致测试失败。
有一种情况除外,模拟固定带宽网络访问的场景,可在局域网中使用限制带宽的手段进行测试。遵循一个原则,测试过程中,任何资源都必须可控。
3、吞吐量
单位时间内系统处理用户请求的数量,可以用请求数/单位时间或者点击数/单位时间,或者字节数/单位时间等方式来衡量,其中通过字节数/单位时间的计算方式,与当前的网络带宽比较,可以找出网络方面的问题。例如,1分钟内系统可以处理1000次转账交易,则吞吐量为1000/60=16.7。吞吐量指标直接体现了软件系统的业务处理能力,尤其适用于系统架构选型,做对比测试。
4、系统资源耗用
系统资源耗用,客户端与服务器系统各项硬件资源的耗用情况,如CPU使用率、内存使用率、网络带宽占用率、磁盘I/O输入输出量等。一个系统的高效运行,除了软件资源外,硬件资源也是不可缺少的部分,因此在性能测试过程中,需关注系统资源的耗用。
5、业务成功率
业务成功率意为用户发起了多笔业务请求,成功的比率有多少。例如,测试银行营业系统的并发处理性能,全北京100个网点,中午12:30到13:30一个小时的高峰期里,要求能支持50000笔开户业务,其中成功率不少于98%,也就是需要成功开户49000笔,其他的1000笔可能是超时,或者其他错误导致未能开户成功。业务成功率展示了在特定压力或负载情况下,服务器正确稳定处理业务请求的能力。
6、TPS
单位时间内服务器处理的事务数,该指标值越大越好。一般情况下,用户业务操作过程可能细分为若干个事务,单位时间处理的事务数越多,说明服务器的处理能力越强。
根据上述各个指标的概念,结合被测对象本身的业务情况,做出如下测试需求及指标分析。
ECShop是一个面向广大网络用户的电子商务系统。大部分用户会在某个时间段访问该电商平台,进行网络购物,但如何确定用户访问的时间段呢?
新系统没有上线时,没有历史数据可以依据,这种情况下,测试工程师可以通过竞品分析,获取友商系统的运营数据作为参考。以淘宝运营数据为例,通过运营团队统计,大部分消费者集中在如图2所示的时间段访问电商平台。