Java并发——volatile关键字
什么是内存可见性?
这里就要提一下JMM(Java内存模型)。当线程在运行的时候,并不是直接直接修改电脑主内存中的变量的值。线程间通讯也不是直接把一个线程的变量的值传给另一个线程,让其刷新变量。下面是一副抽象的结构图。
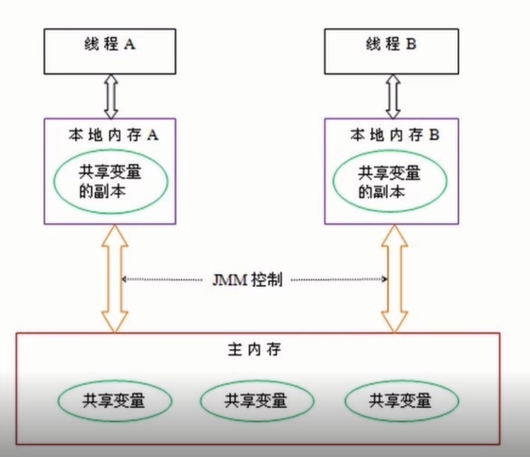
线程A要想和线程B通信,其实是通过改变主内存中的共享变量的值。具体的工作原理就是,线程A不能直接修改主内存中的值,而是在主内存和线程A中需要一个缓存区(每个线程都有自己的一个缓冲区),再将共享变量的副本拷入缓冲区,在缓冲区里修改完之后再通过一些指令将副本改变的值刷新进主内存。这里刷新就会出现很多问题,有可能线程A修改了共享变量的值没有刷新进去,当B需要使用共享变量的时候就会用旧值。所以这就是多线程存在一个比较大的问题。前面介绍的synchronized关键字,以及现在介绍的volatile,后面会介绍的CAS,其实都会解决这个内存可见性的问题。不过实现原理不同。要保证内存可见性也就是每一个线程修改一次共享变量的值,都需要让主内存中的变量刷新,并且让其他线程也刷新共享变量副本。
volatile如何实现内存可见性?
其实volatile的可见性底层原理主要是内存屏障和禁止重排序。内存屏障是在volatile变量读操作之前加入load指令,从主内存中读取最新的共享变量,而不是使用之前的副本值,同样写的时候也是加入store指令,将本地内存中的共享变量值强制刷新到主内存中。这样就保证了每个线程拿到的volatile变量是最新的值。下面是两个示意图
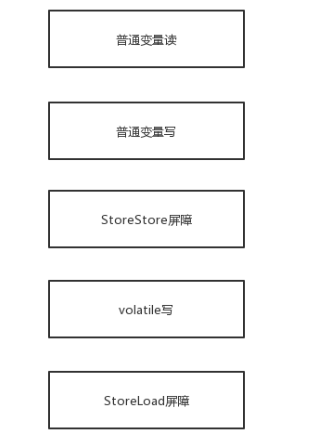
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
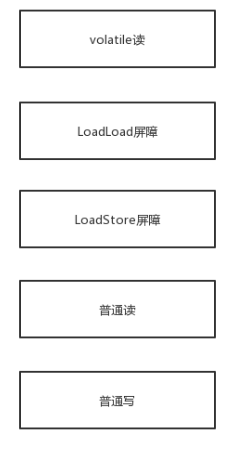
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。也就是
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
上面四个屏障不但会强制变量刷新,而且会防止指令之间的重排序(JVM对于没有数据依赖关系的指令会进行重排序,指令重排序也会导致变量的值读取是错误的)。volatile的底层就是这样实现,较synchronized更为轻量级,毕竟synchronized是用来修饰方法和代码块的,而volatile保证的只是一个变量,所以更为轻量级。
如何优化volatile关键字?
我们先来弄清楚对于英特尔酷睿i7、酷睿、Atom和 NetBurst,以及Core Solo和Pentium M处理器的L1、L2或L3缓存的高速缓存行是64个字节宽,不支持部分填充缓存行。要想优化volatile变量运行速度,只需要将变量追加到64个字节
也就是如果一个volatile变量存入高速缓存且不足64个字节长度,这时候可能在同一个缓存行中就会再存入另一个volatile变量,而由于缓存一致性机制,当处理第一个volatile变量的时候,整个缓存行是锁定的,这时候第二个volatile变量或者缓存行其他变量需要被其他处理器操作就必须等到第一个volatile变量操作完才能进行。如果这时volatile变量是64个字节独占一个缓存行的时候,那么就不会有上面的影响发生。
那么什么时候我们都需要追加64个字节吗?有下面两种情况不需要追加
1、缓存行非64字节宽的处理器。如P6系列和奔腾处理器,它们的L1和L2高速缓存行是32个字节宽。
2、共享变量不被频繁地写。可以看出追加字节的方式是需要性能消耗的,如果共享变量不被频繁地写的话,锁定的概率小,不需要追加字节。